



















Redis Mirroring
Instaclustr has introduced the ability to replicate data written from one Redis cluster to another via a process we call Redis Mirroring.
Redis Mirroring allows writes from one Redis cluster to be replicated to another, by deploying a lightweight proxy called Shotover, co-located with the Redis nodes, which replicates writes to a second, remote Redis cluster.
How to create a Redis Mirroring cluster
- On the console, create a Redis cluster of any size as you normally would and wait for it to enter the Running state.
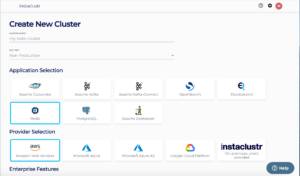
- At this time, Redis Mirroring does not support clusters with client encryption enabled.
- Click your cluster from the left side bar, and you will find a option – Add Data Centre


- Clicking Add Data Centre will take you to the Add Data Centre page, where you can create a new data centre for your Redis cluster by filling in the fields necessary
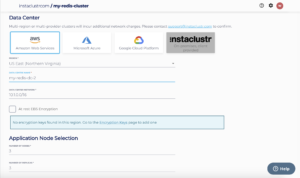

- Make sure both data centres are similarly sized, as they will be expected to hold the same amount of data.
- Once complete, the second Redis data centre will begin to provision in the selected region, wait for it to enter the RUNNING state.
How to use a Redis Mirroring cluster
- Once we have a running Redis cluster with multiple mirroring data centres, we need to configure our client applications to send Redis commands through Shotover application.
- In the Connection Info page, we can find the connection details, which describes the various ways we may connect to our Redis cluster
- We can find a tab page titled Shotover Proxy, which exposes a new port & DNS name that our client applications must use to send Redis commands in order for Redis Mirroring to work.
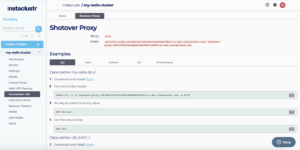

We should select the Redis data centre which is closest to our client application to maximise performance.
Limitations
- The mirroring method is only suitable for use cases where the data has a short time to live (TTL). This is due to the fact that the method for Redis Mirroring is simply asynchronous, on-the-fly replication, so if anything goes wrong there could be missing data on the secondary/standby cluster. There is no record of what has or hasn’t been replicated. The short TTL is so any missing data will matter less, as the data would expire soon anyway. It is hard to put an exact figure on how long your short TTL should be, as it depends on a multitude of factors, but we would say: in the range of minutes.
Need Support?
Experiencing difficulties on the website or console?
Already have an account?
Need help with your cluster?
Contact Support Why sign up?
Spin up a cluster in minutes