In-place Resizing for Elasticsearch
| For Legacy Support Purposes Only |
|---|
Nodes in an Open Distro for Elasticsearch cluster can be resized in-place via the Console or by issuing a request to our Provisioning API. Moving to a new node size lets you scale the CPU core count and memory quotas as well as increase disk capacity to meet changing demands. You may resize a subset of nodes that match a purpose e.g. resize only the master nodes in your cluster.
Preparation
Instaclustr recommends that you first test your applications against in place resizing in a non-production setting to verify that the resize process doesn’t interrupt your applications.
During a cluster resize operation one or more nodes will temporarily become unavailable as they are resized (for resizing involving more than a disk resize). Elasticsearch, as a whole, will handle these transient outages by re-electing masters and re-assigning primary shards, but client applications may need to be programmed with certain considerations in mind.
Instaclustr will only concurrently resize nodes within the same rack, to ensure that replicas stored in other racks remain available during the resize.
Replica Requirements
All Indexes need to be configured to have total replicas equal to the number of racks. i.e. in a 3 rack clusters you will need to setup indexes with 2 replicas (3 = primary + 2 replicas)
Additionally, you may only concurrently resize more than one node at a time in a data centre if:
- The number of racks > number of replicas
Other Constraints
- Current in place resizing is only supported on AWS Nodes which are EBS backed.
- Disks can be increased but not decreased
- Resizing where the disk is modified can only be done once every 6 hours due to EBS limitations
- Resizing only works with single disk node sizes.
- The nodes selected for resize must all be the same size.
Writes
Writes should be performed with appropriate active shard setting to give greater assurance that the write will succeed. Setting active shard wait can be done either via index setting or in indexing API calls. For example setting wait_for_active_shards = total replicas – 1 may be appropriate for tolerating a node going down. Setting this to ‘all’ may result in long indexing waits or failure.
Clients Settings
Clients should use appropriate failure tolerance settings which may differ from client to client. For example it is recommended to use appropriate sniffer setup. Use a sniff on failure or sniff interval rather than on initial setup.
Resizing
To in-place resize a data centre, select the Resize button from the Cluster Details menu for the cluster you wish to resize nodes in.
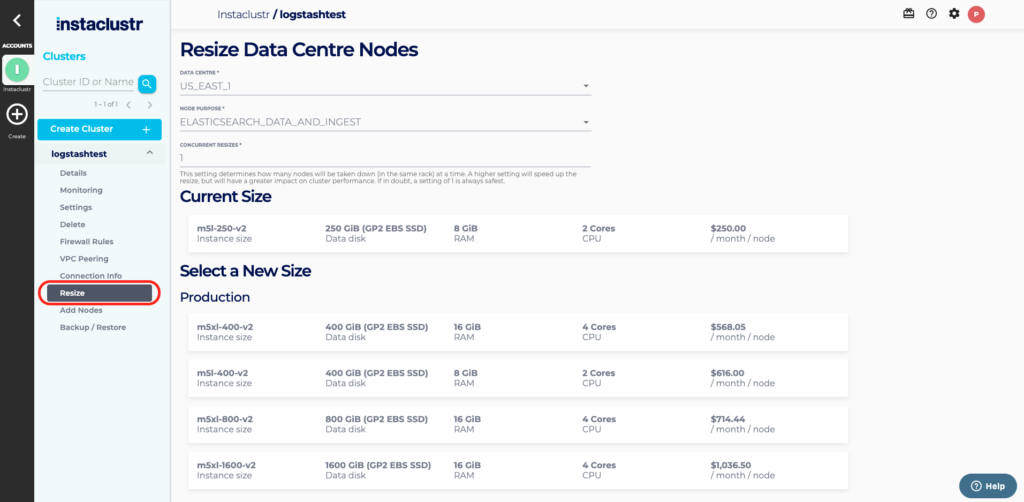
You will be able to select which nodes you want to resize by selecting the node purpose from those available to your cluster. You can resize Master, Data and Kibana nodes. If all nodes are the same size you can resize all nodes by selecting the All Purpose.
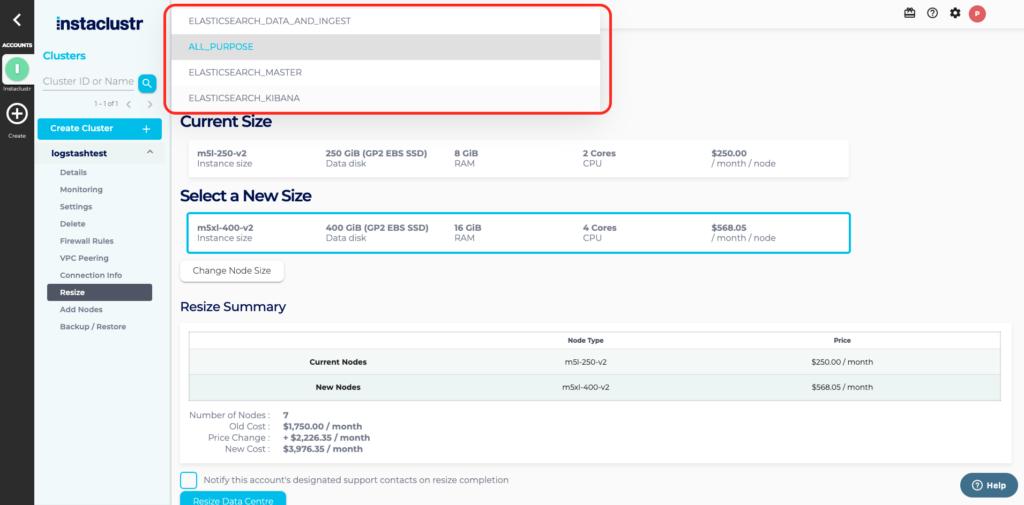
The Resize Data Centre page lets you select the desired target node size from within the size class and specify the resize concurrency factor and notification options. The difference in CPU core count, memory and disk quota and total monthly price are listed on the page.
The Concurrency Factor is a number, from 1 to the count of nodes in the largest rack, that specifies how many nodes may be resized at the same time. Instaclustr will only resize multiple nodes concurrently if they are located in the same rack.
By default Instaclustr will send your accounts’ designated support contacts an email once the resize is complete. You may opt-out of this notification by deselecting the Notify this accounts’ designated support contacts on resize completion checkbox.
If the selected data centre isn’t resizable then an explanation will be displayed on the Resize Data Centre page.
While a resize is in progress, the Cluster Details page will display the progress of the resize. You will see individual nodes switch from Running to Pending → Provisioning/Provisioned and then back to Running once their size has been changed.
In some rare cases, it may be desirable to cancel a resize operation while it is in progress. This can be achieved via the Instaclustr API. This may leave the cluster in a non-uniform state with some nodes already resized. Please contact our support team to assist in this case, to ensure your cluster is correctly sized.