Tutorial: Using Kafka with Amazon S3
In this tutorial, we will learn how to log Kafka data in an AWS S3 bucket by using Kafka Connect and the Bundled Instaclustr S3 connector.
You will need:
- An AWS Account
- An Instaclustr Account
Create S3 Bucket
We begin by creating the S3 bucket in AWS which we will use as the data sink for all of the data sent through a Kafka cluster.
Follow the steps in the AWS documentation to set up an empty S3 Bucket to use for this project:
(Note, although the documentation instructs you to create your Bucket in Oregon, we recommend creating it in whichever region you intend to spin up your Kafka and Kafka Connect Clusters)
https://docs.aws.amazon.com/quickstarts/latest/s3backup/step-1-create-bucket.html
We recommend creating an entirely new S3 bucket for this tutorial to make set-up and testing as simple as possible.
Kafka Connect Configuration
We now switch to the Instaclustr console which will allow us to provision the Kafka and Kafka Connect clusters which we will connect to our S3 bucket. By the time we are finished we will have the following configuration:
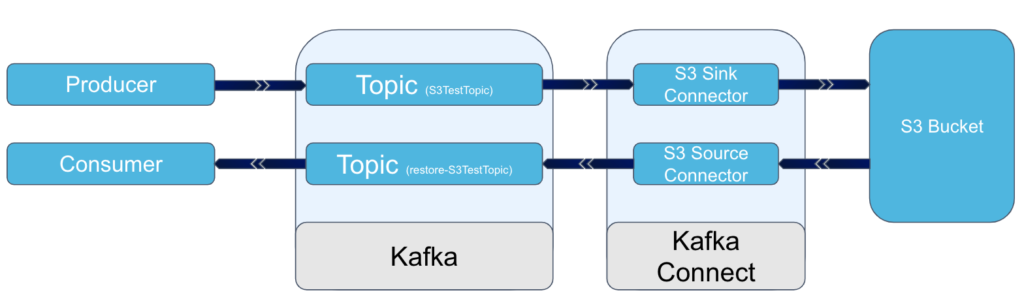
Creating Kafka Cluster
Create a Kafka Cluster in using the Instaclustr console with the following properties (for values which haven’t been provided in the table, use the default values):
| Name: | Kafka_S3_Test_Cluster |
| Security: | Add Local IP to cluster firewall allowed addresses |
WARNING: Ensure that you set the firewall rules of the Kafka cluster so your local machine has access. Later on in the process, we will need to use the CLI to create the test topic in our Kafka cluster and to do this we will need to have access to the cluster.
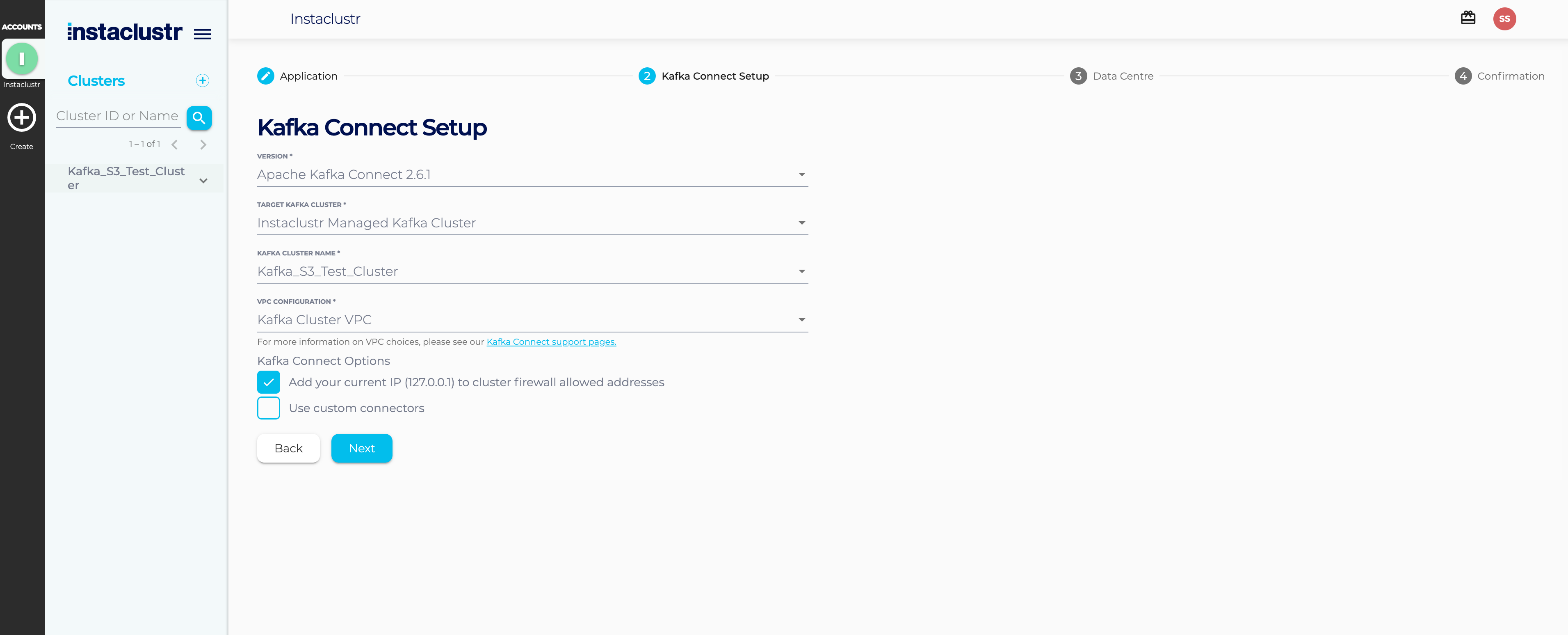
Creating Kafka Connect Cluster
Wait until the Kafka cluster has been created and all the nodes in the cluster are running before creating the Kafka Connect Cluster. The Kafka Connect Cluster is attached to the Kafka cluster we just provisioned and links to our S3 bucket via a custom connector.
Set the target cluster of the Kafka Connect Cluster to be the Kafka cluster which you provisioned in the previous step.
| Name: | Kafka_Connect_S3_Test_Cluster |
| Kafka Cluster Name | Kafka_S3_Test_Cluster |
| VPC Configuration | Kafka Cluster VPC |
| Security: | Add Local IP to cluster firewall allowed addresses |
This should produce a setup like the following in your Instaclustr console:
Ensure both of your clusters are successfully provisioned with a status of “Running” before continuing to the next steps.
Create Kafka Topic
For Kafka Connect to work, sources and sinks must refer to specific Kafka Topics. Create a new Kafka Topic named “S3TestTopic”. For Kafka Connect to work, sources and sinks must refer to specific Kafka Topics. Create a new Kafka Topic named “S3TestTopic”. Instructions can be accessed by Navigating to the ‘Connection Info’ tab of your Kafka Cluster:
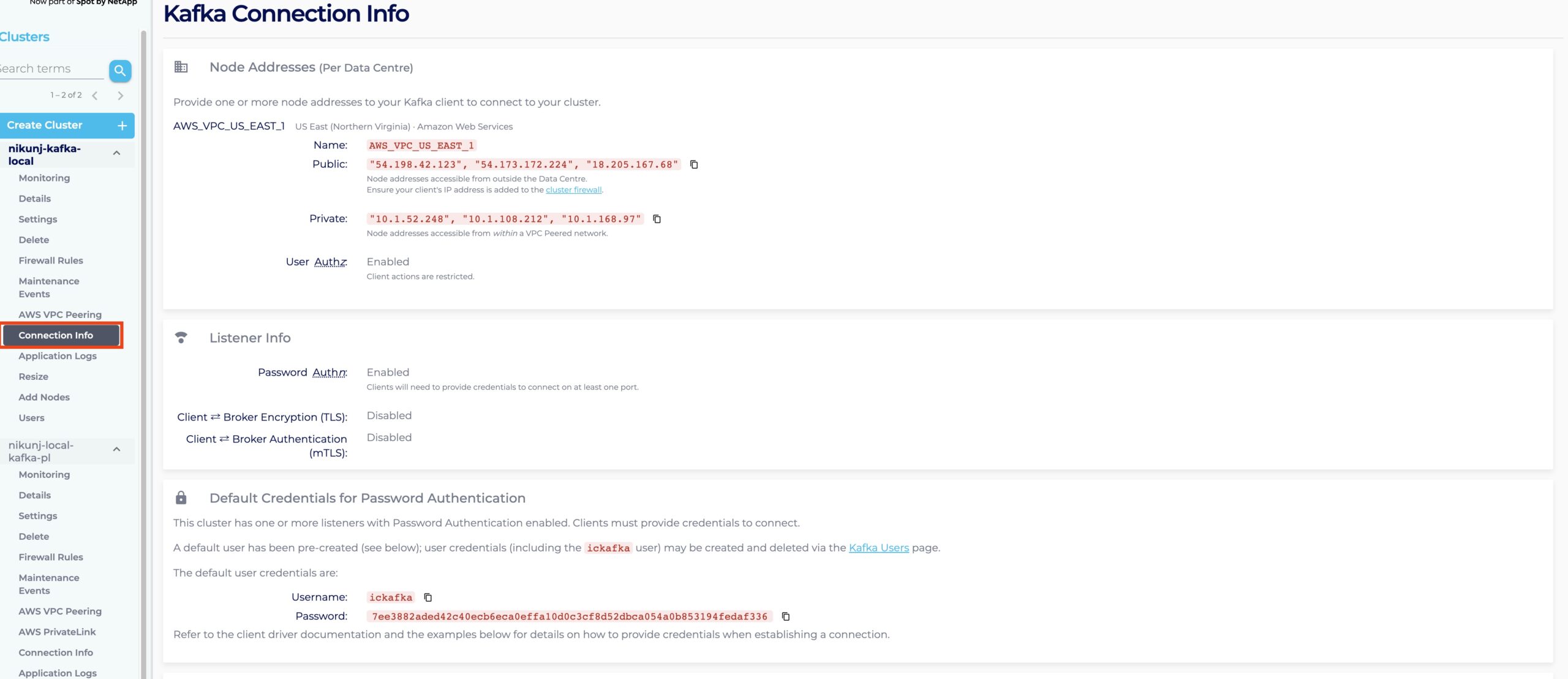
And scrolling down to the ‘Topic Management’ tab of the ‘Examples’ section:
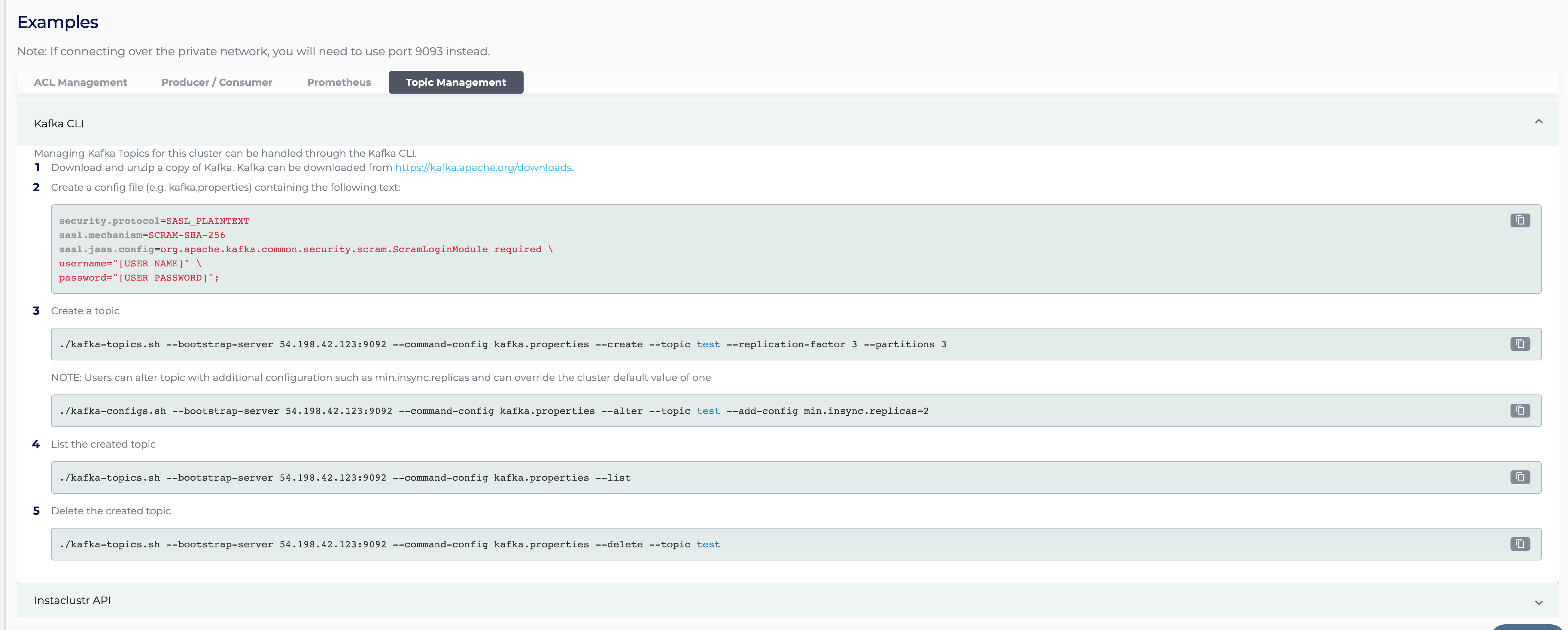
Note that the instructions are for creating a topic named “test”, this argument should be changed in the commands.
Follow the same steps to create a second topic named “restored-S3TestTopic”, this topic will be used for testing purposes when we try to read the contents of our S3 bucket back into Kafka.
Configure Instaclustr S3 Connector
Now that we have a Kafka Cluster and a connected Kafka Connect cluster it is time to add a custom connector to allow us to export all messages sent along the S3TestTopic to our S3 bucket. To do this we use the Bundled Instaclustr S3 connector.
The configuration options for the Kafka Connect S3 Plug In are found here: https://www.instaclustr.com/support/documentation/kafka-connect/bundled-kafka-connect-plugins/instaclustr-aws-s3-kafka-connect-plugins/
Run the curl command shown below to set up the custom connector to your S3 bucket. Note that in the example below the prefix is empty so all messages will be written to the root directory of the bucket.
| <ip-address-kafka-connect-node> | This is the public ip address for any one of the nodes in the kafka connect cluster. |
| <s3-bucket-name> | This refers to the name of the S3 bucket we created in the first step: provides a reference so the connector knows where to write to |
| <aws-access-key> | The access key for an AWS account which has read and write access to the S3 bucket |
| <aws-secret-key> | The secret key for an AWS account which has read and write access to the S3 bucket |
| <ic-kc-password> | This is the password for the kafka connect cluster you provisioned in one of the previous steps. This value can be found by selecting your Kafka Connect cluster in the instaclustr console and navigating to the “Connection Info” tab. Importantly this value will be different to the password for your Kafka Cluster which you used in the previous step. |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
curl https://<ip-address-kafka-connect-node>:8083/connectors -X POST -H 'Content-Type: application/json' -d '{ "name":"sink", "config":{ "connector.class":"com.instaclustr.kafka.connect.s3.sink.AwsStorageSinkConnector", "tasks.max":"3", "topics":"S3TestTopic", "prefix":"", "aws.s3.bucket":"<s3-bucket-name>", "aws.accessKeyId":"<aws-access-key>", "aws.secretKey":"<aws-secret-key>", "value.converter":"org.apache.kafka.connect.converters.ByteArrayConverter", "key.converter":"org.apache.kafka.connect.converters.ByteArrayConverter" } }' -k -u ic_kc_user:<ic-kc-password> |
WARNING: Ensure that you set the firewall rules of the kafka Connect cluster so your local machine has access. Otherwise, when you run this curl command on your machine it won’t be able to reach the Kafka connect Cluster.
Start Test
We have now set up our Kafka Connect and S3 configuration. It is now time to test our set up by configuring a console producer and sending some messages to our kafka cluster.
|
1 |
./bin/kafka-console-producer.sh --broker-list <broker1>:9092,<broker2>:9092,<broker3>:9092 --producer.config <path-to-kafka.properties> --topic S3TestTopic |
This should open a command line prompt to enter messages. Start writing some messages to your producer, the contents of your messages are not important but we recommend you enter sequential values such as “message 1”, “message 2”, “message 3”, etc. as this will make the verification process easier.
|
1 2 3 4 |
> message 1 > message 2 ... > |
After entering a series of messages it is time to check if what we have sent via our console producer has appeared in the S3 bucket. To do this we use the AWS CLI.
Run the following command to view the contents of the bucket:
|
1 |
aws s3api list-objects --bucket "<name-of-s3-bucket>" |
It should show a log of the messages you have just added.
If you inspect one of the messages either through the AWS console or downloading it via the AWS CLI you will find it is in binary format.
Because the binary format is hard to read we instead have opted for using the source connector to restore the messages to Kafka and then reading them through the kafka console consumer.
Configuring Bundled S3 Source Connector
This connector is used to read data back into the kafka topic which was written by the Bundled S3 Sink Connector.
To create this connector we use the following curl command:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
curl https://<ip-address-kafka-connect-node>:8083/connectors -X POST -H 'Content-Type: application/json' -d '{ "name":"source", "config":{ "connector.class":"com.instaclustr.kafka.connect.s3.source.AwsStorageSourceConnector", "tasks.max":"3", "kafka.topicPrefix":"restored", "s3.topics":"S3TestTopic", "aws.s3.bucket":"<s3-bucket-name>", "aws.accessKeyId":"<aws-access-key>", "aws.secretKey":"<aws-secret-key>", "value.converter":"org.apache.kafka.connect.converters.ByteArrayConverter", "key.converter":"org.apache.kafka.connect.converters.ByteArrayConverter", "prefix":"" } }' -k -u ic_kc_user:<ic-kc-password> |
The values for <s3-bucket-name>, <aws-access-key>, <aws-secret-key> and <ic-kc-password> are the same as the values used for configuring the s3 sink connector previously.
Configuring Kafka Console Consumer
We now use a console consumer to read the messages which are sent back through Kafka by our Bundled S3 Source Connector.
Instructions to set up a console consumer can be found in the Kafka cluster’s ‘CLI’ examples in the console, next to the ‘Topic Management’ examples we visited earlier for setting up our topics. The console consumer should be set to read from the “restored-S3TestTopic”. As you type messages into the console producer, they will be sent through both of the S3 bundled plugins and reappear in the console consumer.
Congratulations, you have successfully connected a Kafka cluster to an AWS storage bucket using Kafka Connect and Instaclustr’s S3 plug in.