



















Accessing Monitoring Information
- To access monitoring tools, log into Instaclustr console.
- Click Monitoring from the sidebar menu of your Kafka cluster. This opens the cluster Monitoring page.
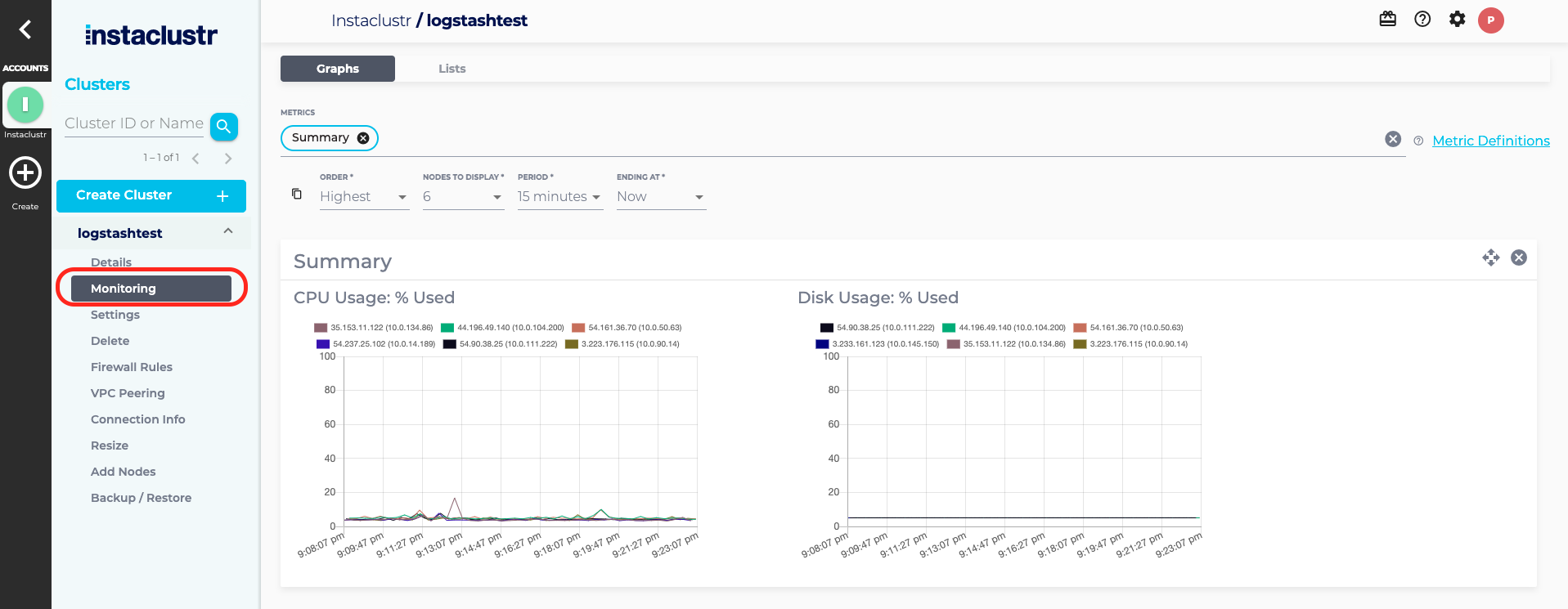
- The cluster Monitoring page displays monitoring information such as CPU and Disk usage for all the nodes in the cluster. The menu bar allows you to select a number of metric groups from a dropdown menu and to customise how you wish to view the selected metrics. Refer to our support article on The Monitoring Page for more information on the available features.

- For information on how to monitor a Kafka Cluster via the Instaclustr Monitoring API, refer to our support article on the Instaclustr Monitoring API.
Note: Our monitoring system collects all metrics every 20 seconds from Kafka. Events that occur for less than 20 seconds are therefore not captured.
Need Support?
Experiencing difficulties on the website or console?
Already have an account?
Need help with your cluster?
Contact Support Why sign up?
Spin up a cluster in minutes